|
|

章节 C – 二硫键和多链1 – 获取序列 – 简单方法如果您知道某个序列的序列号,无论来自哪个蛋白质数据库,您都可以最简单地通过在主工具栏的网页访问输入框
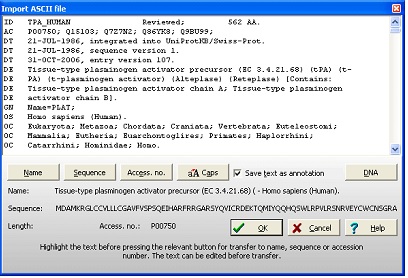
无论搜索哪个数据库,结果都将在 "Import ASCII file" 对话框中呈现: 由于GPMAW识别Swiss-Prot和Entrez的格式,记录将被解析为相关部分(即序列名称、序列本身和序列号)。这些可以在记录下方查看。如果未显示序列,您必须手动选择:高亮显示记录中代表名称的部分,然后单击 "Name" 按钮。高亮显示序列号,然后按 "Access. No." 按钮。滚动到记录的底部,高亮显示序列并按 "Sequence" 按钮。注意,由于GPMAW仅导入当前质量文件中定义的单字母代码,空格字符、数字、反斜杠等将被忽略且不会导入。 按 "OK" 按钮将序列导入GPMAW序列窗口。如果勾选 "Save text as annotation"(默认),整个注释将保存在注释窗口中,并将与序列一起保存,以便您日后访问。注意:对话框的顶部是一个编辑框。这意味着您可以在将文本导入序列窗口之前编辑文本。 2 – 获取序列 – Entrez(万维网)如果您不知道某个序列的序列号,如果网页检索不起作用,或者您只是在浏览网页时偶然遇到一个有趣的序列,那么了解GPMAW具有非常灵活的序列输入系统是很有好处的:对于本示例,我们将从网上最受欢迎的分子生物学网站之一NCBI网站(http://www.ncbi.nlm.nih.gov/)获取我们的序列。该网站由Entrez搜索引擎驱动,我们将在蛋白质数据库中搜索。 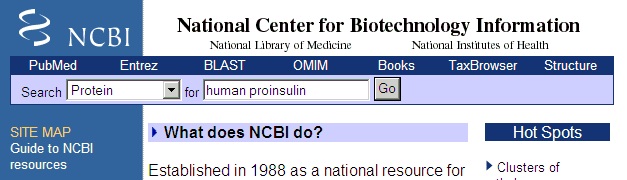
在左侧下拉框中选择 "Protein",并在搜索框中输入 "human proinsulin"。按Enter键或单击go按钮。
搜索结果默认以GenPept格式显示。这是可以的,因为我们将通过这种方式获得大部分附加信息。
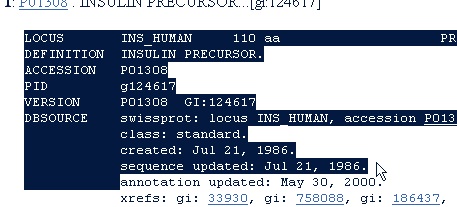
现在按Ctrl-C将条目复制到剪贴板。移动到GPMAW并选择 File|Import text (ASCII)|from clipboard。 "Import ASCII file" 对话框将打开,顶部编辑框中有来自Entrez的条目,请参阅上一页的图片。由 于GPMAW识别GenPept格式,数据库条目已经解析为 "Name"、"Sequence" 和 "Accession number"。确保勾选"Save text as annotation",以便将完整条目保存在GPMAW序列的注释页面中。 选择"OK",整个序列被导入GPMAW并打开一个单独的窗口。
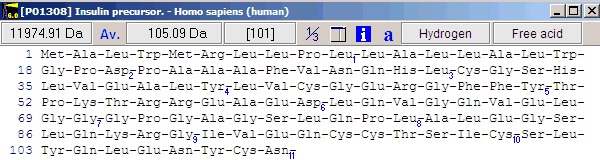
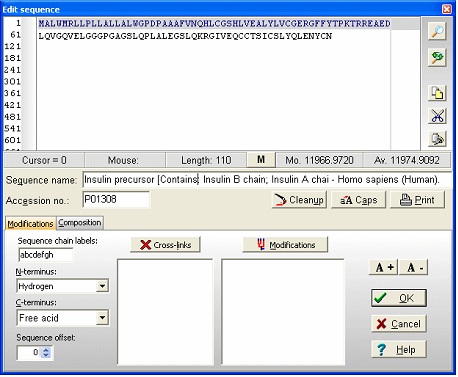
请注意,本地工具栏中的"a" 按钮是蓝色的,表示注释页面中有信息(单击按钮查看完整注释)。按钮的颜色表示内容类型:灰色:无内容;蓝色:Entrez格式;绿色:Swiss-Prot格式;红色:有内容,但不是可识别的格式。 现在选择 File|Save as 以保存序列。在 "Save sequence" 对话框中,输入 "human insulin",然后按 "OK"。或者,您可以保存到已存在的序列文件,从而创建序列库。通过将多个序列保存到同一个库中,您可以大大减少硬盘上的混乱。 3 – 编辑序列我们现在有了胰岛素前体,但我们想要处理胰岛素的活性形式。首先我们需要知道活性部分在序列中的位置。单击红色的"a" 按钮(或选择Info|Annotation)。这将打开注释页面,其中包含来自Entrez(Swiss-Prot)的完整数据库记录。有趣的部分靠近页面底部,内容如下: FT SIGNAL 1 24 FT CHAIN 25 54 INSULIN B CHAIN. FT PROPEP 57 87 C PEPTIDE. FT CHAIN 90 110 INSULIN A CHAIN. FT DISULFID 31 96 INTERCHAIN. FT DISULFID 43 109 INTERCHAIN. FT DISULFID 95 100 我们需要的信息是,A链从39到59,B链从1到38。 当然有几种制作这些链的方法,但最简单的方法是首先打开序列编辑器:选择适当的序列窗口并选择 Edit|Edit sequence…;或者,您可以在序列窗口中右键单击以打开弹出菜单并选择Edit|Edit sequence。 这将打开序列编辑器,编辑字段中包含胰岛素前体。
现在我们从C端开始,以免改变原始编号。编辑框正下方的状态行指示文本光标右侧的残基。第一步是使用破折号("-")字符分隔链,该字符用作链分隔符。 为此,在序列末尾输入一个破折号("-")。移动光标使其位于89和90之间,然后输入另一个破折号。在54和55之间执行相同操作。 将光标定位在残基24之后,高亮显示到序列的开头。编辑器看起来如下所示: 
删除高亮显示的部分,因为这不是成熟蛋白链的一部分。高亮显示从RRE到QKR-的中间部分并删除它。高亮显示从GIVE到YCN-的最后一个肽段(A链)。剪切到剪贴板(Ctrl-X或使用右侧控制面板中的按钮),将光标移动到行首并粘贴序列。最后移动到序列末尾并删除破折号。 您现在拥有了最终的胰岛素分子:
从名称行中删除 "Precursor" 一词,您就完成了。选择"OK" 将带您回到序列显示。二硫键本可以在序列编辑器中输入,但从序列窗口输入也同样容易。 
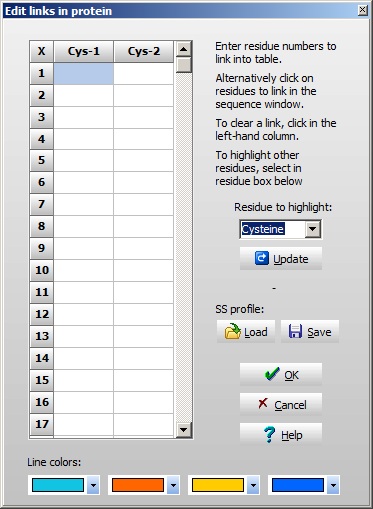
在处理多链时,有几个值得注意的事情: "破折号"链分隔符字符在3字母代码中变成三个破折号,前后各有一个破折号,总共五个破折号。链被命名为a、b、c等(从N端开始计数),正如您可以从指向B链中残基3的光标看到的(工具栏中的第三个位置面板显示[3b])。对于每个链分隔符,相对于单链分子,分子质量增加18 Da。注意:在序列编辑器中,您可以在 "Sequence chain labels:" 字段中更改链的命名,即如果您想要l和h(对于轻链和重链),只需在字段中输入l和h作为前两个字符。 4 – 二硫键我们仍然需要定义二硫键。从上面查看的注释页面,我们可以看到存在以下二硫键:A链第一个到第三个,B链第二个到第一个,以及A链最后一个到B链最后一个。在查看注释信息时,请记住A链在前体的线性序列中位于B链之后。右键单击序列并从弹出菜单中选择 Edit | Edit cross-links 或从Edit主菜单中选择Edit cross-links(您也可以使用键盘快捷键Ctrl + F11)。交叉链接对话框一打开,Cys残基就会被着色,因为这是默认的交叉链接残基。 序列现在看起来像这样: 
如果您想链接其他残基,只需在右侧的下拉框中选择,然后单击 "Update" 按钮以刷新序列窗口。 如果您有多个想要相同二硫键模式的序列(例如,如果您有多个IgG序列),您可以将模式保存到磁盘并为下一个序列重新加载。该模式基于链接残基1到链接残基4等,而不是基于特定的序列位置。这即使序列中有插入和缺失也能转移模式。 在窗口底部,您可以选择用来绘制连接Cys线条的颜色。 选择"OK",您将返回到序列窗口,其中定义的交叉链接以红色显示:

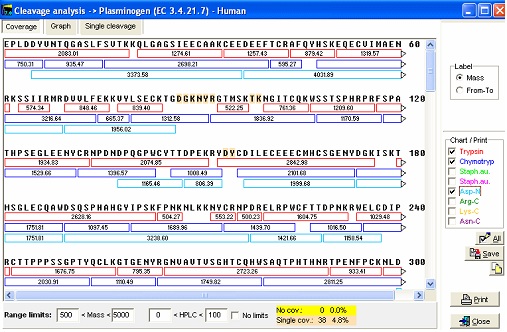
半胱氨酸可以处于氧化状态(S-S,交联)或还原状态(SH)。这在GPMAW中由主工具栏中的SS按钮控制。当按钮显示"SS"时 使用命令保存文件。这将保存到同一文件(如果是库文件,则保存到同一位置)。如果您使用 File|Save as 命令保存到同一文件,序列将被附加到序列文件,从而生成序列库(如果文件还不是库)。如果您将其附加到现有文件,则最好重命名序列名称以区别于以前保存的序列(例如,在名称开头添加 "Cross-linked")。 注意:如果您从Swiss-Prot数据库导入序列,数据库注释将最终位于序列的注释页面上。GPMAW能够解释此注释的 "Feature" 部分,因此您只需单击几下鼠标即可将二硫桥直接导入到序列中(如果它们是注释的一部分,通常情况如此)。功能应在更改序列长度之前导入。有关更多信息,请参见第C.1-2节、手册和在线帮助。 5 – 切割蛋白质 – 也包括连接的肽段将蛋白质切割成肽段通常使用特定的蛋白酶或化学方法。GPMAW使用非常灵活的符号,使您能够指定多达大约16个位置,包括"必需残基"、"非切割残基"、"多个独立特异性"等。此外,您可以启用"漏切割",专注于质量范围,修饰肽端点,执行氘交换等。有关详细信息,请查阅在线帮助和手册的第9章。切割连接的肽段通常与切割非交联序列相同,只有一些小的差异。 选择用于切割的酶时要做的第一件事是高亮显示参与特定切割的残基(例如,胰蛋白酶的Arg和Lys,内切蛋白酶Glu-C的E,胰凝乳蛋白酶的Trp、Phe和Tyr等)。由于程序对不同的残基选择使用不同的颜色,您可以查看生成的肽段。通常可以清楚地看到切割困难的特定区域(即切割距离很远或特别近的区域——产生非常长或非常短的肽段,两者都可能难以分离和分析)。与大多数情况一样,以单字母代码查看序列时,更容易获得序列的概览。 另一种方法是选择 Cleavage|Cleavage analysis 对话框。 该窗口由三个选项卡页面组成,其中第一个页面使您能够查看自动切割列表中列出的前8个酶生成的肽段。 在右侧面板中选择切割试剂。主窗口以单独的颜色显示生成的肽段。
底部面板使您能够仅显示某些肽段,即排除小或大的肽段或排除非常亲水或疏水的肽段。 如果勾选 "No limits" 复选框,将显示所有肽段。 通过单击不同的切割剂,您可以快速选择产生最佳大小肽段的酶。 graph页面显示按质量范围划分的肽段数量,Single cleavage页面显示肽段摘要以及显示高亮残基显示切割点的序列。 注意:覆盖页面可以 "Coverage analysis" 格式保存到磁盘,使您能够与获得的实际序列覆盖进行比较。请参阅本手册的末尾。 对于在上面设置中分析的纤溶酶原,胰凝乳蛋白酶似乎是用于一般分析的非常合适的酶(除了它并不总是像其他几种酶那样清洁地切割)。现在您切换回序列窗口并单击剪刀按钮旁边的向下箭头。这将打开 "Quick-cleavage" 菜单,您可以在其中从 "Automatic digest" 列表中的前10个条目中进行选择。该菜单没有给您很多选项,只有菜单底部的 "1 missed cleavage" 和 "Digest all sequences",但这通常就足够了。如果您需要更多选项,单击 "剪刀" 按钮以获取完整选项。从下拉菜单中,您现在选择"Chymotrypsin /W,/Y,/F-\P",肽段窗口打开: 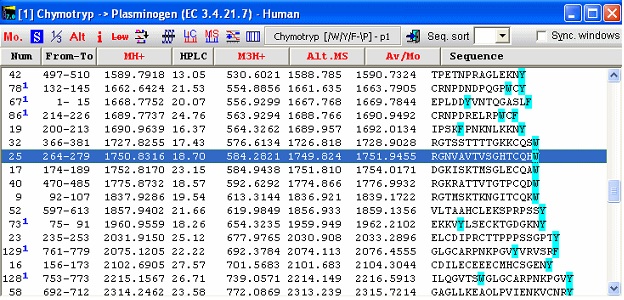
第一列始终显示蛋白质切割中的肽段编号。在这种情况下,生成66个肽段作为"清洁"切割,因此上面的数字表示肽段包含漏切割位点。数字后面的蓝色上标表示漏切割的数量。注意,肽段19包含一个FP位点,该位点未被切割,因为酶规格规定切割不会发生在脯氨酸残基之前。因此这不计为漏切割。 每一列都包含给定肽段的指定信息。目前可以选择19种不同的格式,从质量、各种电荷下的m/z,到pI、HPLC保留指数到交替质量表等。有关完整列表,请参阅在线帮助、手册和侧边栏。 请注意,在窗口中,序列窗口中残基的着色已经延续到肽段窗口中。除了"正常"信息外,连接的肽段显示在所有非连接肽段之后的底部。第一列显示连接的肽段编号,最后一列显示肽段的质量。非连接肽段可以通过单击相应的标题按任何列排序。第二次单击以反转排序顺序。肽段窗口的工具栏可以访问许多功能。从左到右:更改质量类型;设置肽段列表属性;1-/3-字母残基显示;交替列显示;肽段信息(首先选择适当的肽段);从列表中移除低质量肽段(截断值在*Setup*中设置);在列表中显示部分修饰;ms/ms切割(首先选择肽段);模拟HPLC色谱图;模拟HPLC色谱图;电荷与pI图(首先选择肽段),以及等电聚焦凝胶。勾选 "Sync. Windows" 复选框将导致在父序列窗口中为选定的肽段加下划线。 如果您在窗口中右键单击,您将在弹出菜单中获得其他选择。
在线留言尊敬的客户朋友,如您有任何意见建议,请通过下表反馈给我们,我们会尽快与您联系。
|
|
|
||||||||||||||||||||||||