|
|
 章节 D – 翻译后修饰1 – 获取序列 – Swiss-Prot这次我们将从 Swiss-Prot 数据库中检索一个序列。Swiss-Prot/UniProt 数据库随 GPMAW 原始安装 CD-ROM 提供。数据库无法直接从 CD-ROM 访问,因此您必须使用安装程序将其复制到硬盘上(可以在 GPMAW 主安装之后进行)。如果您没有 CD-ROM,或者需要数据库的更新版本,您可以从互联网下载(例如 ftp.ncbi.nlm.nih.gov、ftp.ebi.ac.uk、ftp.expasy.ch),但在搜索数据库之前,您必须将其转换为 FastA 格式并使用 Dbindex 实用程序对其进行索引。
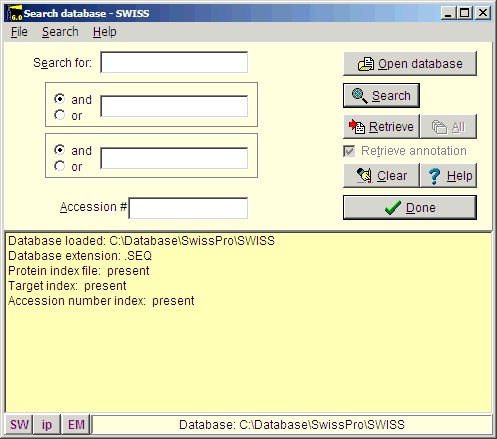
选择 File|Open Database| FastA(或点击主工具栏中的 FastA 按钮),搜索数据库对话框(右侧)将打开。首次打开对话框时,它将是空的,您必须导航到相关的数据库文件(带有 .trg 扩展名)才能访问它。一旦访问,程序就会"记住"数据库(或者更确切地说是最近访问的 5 个数据库),您可以通过按下对话框左下角的相应按钮直接打开它(按钮显示数据库名称的前两个字符,悬停帮助显示全名),或者您可以在 File 菜单项的底部访问它。 从 CD-ROM 安装 Swiss-Prot 数据库后,按 'Open database' 按钮,在 'Open' 对话框中导航到 Swiss-Prot 数据库。当找到正确的数据库目录时,选择文件 'swiss.trg'。 当 'Search database' 对话框打开时,您将看到数据库的信息(见上文)。您可以在标题(Swiss)中看到所选数据库,在对话框底部的状态行中可以看到数据库的完整路径。将来访问 FastA 搜索时,您可以在主菜单中选择 File| Open FastA database 或对话框底部的按钮。 检索序列的最快方法是使用登录号(如果已知)。只需在 'Accession #' 字段中输入登录号(例如 P23805),按搜索按钮,蛋白名称将显示在结果框中: 
高亮显示名称并按 'Retrieve' 按钮,序列将以序列窗口的形式导入 GPMAW。如果选中了 'Retrieve annotation' 复选框(默认为"开"),整个数据库条目将被复制到序列窗口的注释页面。 如果您不知道登录号,则必须根据蛋白名称以及可能还有物种进行搜索。请记住,您正在搜索数据库的 FastA 格式版本,而不是整个数据库(即使您将检索完整的数据库条目)。因此,您只能使用数据库条目名称行中存在的词语。该行通常也会保存物种名称。如果您需要在数据库条目的其他部分进行搜索,则需要使用网络搜索引擎之一(例如 Swiss-Prot 数据库的 EBI,www.ebi.ac.uk,或 Expasy,www.expasy.ch)。
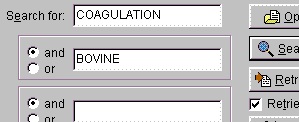
您也可以输入 'factor',但搜索返回的条目很少,所以这并不重要。通常,您对搜索参数使用 'and'(在这种情况下是 'coagulation and bovine'),但您也可以使用 'or'(仅对两个参数可靠地工作)。如果您得到 'I/O error 87',则您的搜索词太宽松,您必须缩小范围。您应该始终将最具选择性的术语放在第一位(例如,如果您使用 'human',将其作为最后一个术语)。
2 – 插入翻译后修饰如果您按照上面的说明从 Swiss-Prot 数据库检索了序列,您应该在序列工具栏中有一个绿色的 'a'。如果 'a' 不是绿色的,并且注释页面中没有信息,您应该返回并确保在 'Search database' 对话框中选中了 'Retrieve annotation' 复选框(或者数据库中没有注释可检索,这是因为缺少完整的数据库或交叉索引文件不起作用)。如果您仍然没有获得注释,则您的序列数据库设置不正确,您应该重新安装它(例如,通过使用 CD-ROM 上的安装程序或重新索引下载的数据库)。请注意,当您使用其他数据库(如 EMBL-nr 或 NCBI-nr)时,您将不会获得注释,因为这些数据库最初是 FastA 格式的,除了名称、登录号和序列之外不包含其他信息。 点击序列窗口工具栏中的绿色 'a'。查看注释中的二级修饰,对于人因子 X(2 列),它们应该如下所示: FT SIGNAL 1 ? FT PROPEP ? 40 FT CHAIN 41 180 FACTOR X LIGHT CHAIN. FT CHAIN 183 492 FACTOR X HEAVY CHAIN. FT PROPEP 183 233 ACTIVATION PEPTIDE. FT CHAIN 234 492 ACTIVATED FACTOR XA, HEAVY FT CHAIN. FT PROPEP 476 492 MAY BE REMOVED BUT IS NOT FT NECESSARY FOR ACTIVATION. FT DOMAIN 86 122 EGF-LIKE 1, CALCIUM-BINDING FT (POTENTIAL). FT DOMAIN 125 165 EGF-LIKE 2. FT DOMAIN 234 492 CATALYTIC. FT MOD_RES 46 46 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 47 47 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 54 54 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 56 56 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 59 59 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 60 60 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 65 65 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 66 66 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 69 69 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 72 72 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 75 75 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 79 79 GAMMA-CARBOXYGLUTAMIC ACID. FT MOD_RES 103 103 HYDROXYLATION. FT BINDING 200 200 SULFATE (IN SOME MOLECULES). FT CARBOHYD 208 208 FT CARBOHYD 218 218 N-LINKED (GLCNAC...). FT CARBOHYD 485 485 FT ACT_SITE 275 275 CHARGE RELAY SYSTEM. FT ACT_SITE 321 321 CHARGE RELAY SYSTEM. FT ACT_SITE 418 418 CHARGE RELAY SYSTEM. FT DISULFID 90 101 FT DISULFID 95 110 FT DISULFID 112 121 FT DISULFID 129 140 BY SIMILARITY. FT DISULFID 136 149 BY SIMILARITY. FT DISULFID 151 164 BY SIMILARITY. FT DISULFID 172 341 INTERCHAIN. FT DISULFID 240 245 FT DISULFID 260 276 FT DISULFID 389 403 FT DISULFID 414 442 BY SIMILARITY. 由于这是 Swiss-Prot 注释,GPMAW 有两种将修饰插入序列的方法,一种是手动方法,一种是半自动方法。由于手动方法通常适用,因此将首先介绍它。 翻译后修饰的手动方法:当您想向序列添加翻译后修饰时,您可以将其作为"新"残基或附加修饰添加(见下文)。如果您有大量残基和/或您定期分析该残基,则应使用"New residue"。另一方面,如果您只有少量某种类型的修饰,则应使用"Add-on modification"。
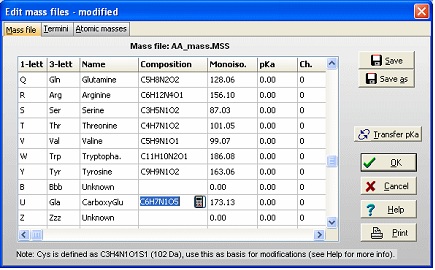
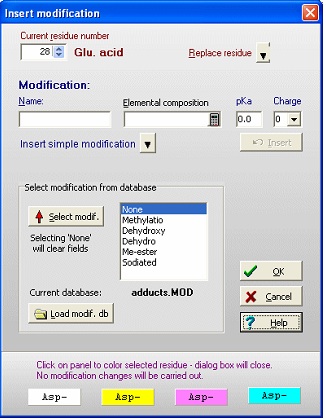
第一个任务是在 GPMAW 中创建一个"新"氨基酸残基。从主菜单中选择 Edit|Edit mass file。滚动残基列表,直到您到达质量列表的"Unknown"部分。 由于所有 1 字母代码必须是唯一的(并且不是标点符号,'-'或'$'),请选择 1 字母代码 'U'。"未知"残基的默认值是 3 字母代码是 1 字母代码的三元组,但由于它只需要是唯一的,因此将 3 字母代码更改为 'Gla',名称更改为 CarboxyGlu。您从 Glu (C5H7N1O3) 复制氨基酸组成并将其粘贴到组成字段中。然后双击组成以调用"元素组成"编辑器,并将 'C' 原子的数量增加一个,'O' 的数量增加两个。或者,您可以直接编辑该字段(点击两次或选择并按 F2)。 使用 'Save' 按钮保存文件。如果您只希望在特殊情况下使用该修饰,则可以使用 'Save as' 按钮并为其指定一个唯一的名称。然后,您可以通过主工具栏中的质量文件选择框选择该文件。返回序列窗口并开始编辑(Edit|Edit sequence)。首先将 N 末端的 12 个 Glu 残基(残基 46、47 … 79)更改为 'U'(我们新的 carboxyglu)。请记住,序列编辑器中的 'Cursor' 字段报告光标__之前__的残基数。 'Add-on' modification:单个残基的修饰可以从序列编辑器或序列窗口执行:
对话框底部的面板将使用显示的背景色在序列窗口中为残基着色(对话框将立即关闭)。 位置 208 和 485 的残基是 O-糖基化的,218 是 N-糖基化的。注释中未提及实际的碳水化合物基团,您必须参考主要文献以确定要在序列中输入的实际修饰。N-连接的糖基化可能相当异质,识别确切的糖基化模式可能很困难 – 请参阅下面 C.3 节中的糖基化工具。 现在,您可以按照胰岛素的先前示例,点击 'Cross-links' 按钮输入二硫键。
在序列编辑器中,您现在可以在残基 233(激活肽)之后插入一个切割(破折号字符 '-'),并去除初始的 40 个残基(信号肽和前肽)。点击 'OK',您将获得最终编辑的序列: 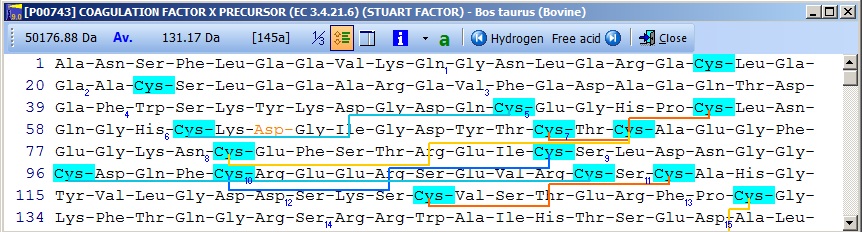
请注意,Cys 残基已高亮显示,以便更好地定位它们。N 末端区域的 Glu 残基正确标记为 Gla。修饰的 Asp 残基为红色(如果您将鼠标光标移到它上面,您可以在右上角看到实际的修饰),并且交联显示为红线。如果您点击主工具栏中的 'SS' 按钮,您将"还原"半胱氨酸(每个 Cys 的质量将增加一个 Da),并且交联将变灰。 翻译后修饰的半自动方法:如果您导入了带有完整注释的 Swiss-Prot 记录,序列窗口上的 'a' 按钮将为绿色。如果您按下此按钮,"注释窗口"将打开,向您显示完整的注释。这是一个两页窗口,激活第二页,"Feature table",将向您显示以下视图: 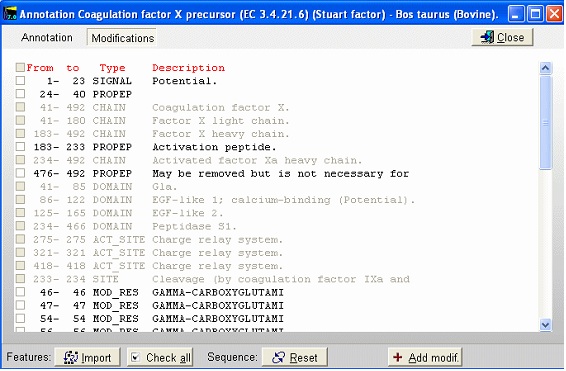
这是 Swiss-Prot 记录的 FT(特征)部分。GPMAW 识别的部分以黑色显示,而无法识别的部分变灰。您现在可以选中要导入序列的特征,按下"Import"按钮将关闭窗口并将修饰传输到序列窗口。如果程序无法传输某些项目,对话框将通知您。修饰的残基将作为残基的单独修饰传输。信号肽和前肽将从序列中删除。请记住先导入残基修饰,然后再导入改变序列长度的修饰。您可以在同一个"导入"会话中包含这两种类型,因为 GPMAW 将最后进行大小修改。一旦您更改了蛋白质的大小,GPMAW 将无法传输残基特异性修饰 – 在这种情况下,您将必须"重置"序列(即删除所有修饰并返回注释中列出的序列)。 您可以通过 '+ Add modif.' 按钮添加自己的修饰。请注意,只能添加 Swiss-Prot(和 GPMAW)中定义的简单修饰。请记住在进行更改后保存。 3 – N-连接糖基化在 MALDI 质谱图中,通常通过观察峰之间约 291 Da 的质量差来检测 N-连接糖基化,这是由不同糖基化形式之间的唾液酸差异(或质谱仪中唾液酸的部分丢失)引起的。 使用因子 X 蛋白并进行胰蛋白酶消化,您可以按以下步骤进行:从快速颜色菜单中选择 'Basic residue',然后选择 'N-glycosylation'。 现在,您可以轻松定位胰蛋白酶切割位点和 N-糖基化位点。 
仔细观察此序列,您将注意到此糖基化的鉴定可能很困难:Asn178 位于一个相当大的肽段(未修饰时为 4082 Da)中。末端的 Arg 就在糖基化残基之后,因此可能会干扰切割。肽段之前的切割是双 Arg,这 again 可能导致异质性(错失切割)。考虑到这一点,您可以模拟切割(Cleavage|Automatic digest…)。在消化参数中,选择部分程度为 2(= 最多两次错失切割),以便将异质性包括在生成的肽段中。在生成的肽段框中,您可以轻松定位潜在的 N-糖基化肽段为编号 18。 
右键单击肽段并从弹出菜单中选择 'N-glycosylation'。 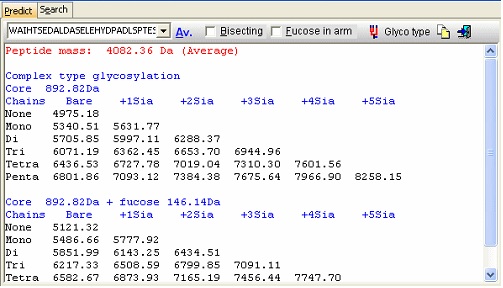
在生成的对话框中,您现在获得与所讨论的肽段链接的最常见的"复合型"糖基化的质量列表。选中 'Bisecting' 框以添加分支 GlcNAc,或选中 'Extra fucose' 以向碳水化合物链添加额外的岩藻糖残基。'Glyco type' 按钮切换显示以显示高甘露糖结构的质量。 如果切换到 'Search' 页面,您可以使用质量列表(例如,通常来自 ms/ms 实验)来搜索有效的糖基结构。由于结构数量是天文数字,因此仅对上述的"标准"类型(+/- 岩藻糖)加上或减去 'sugars.mod' 修饰文件中定义的任何糖进行搜索。 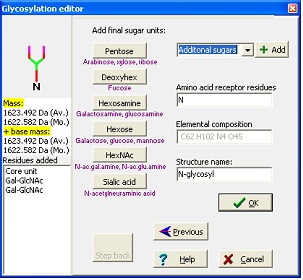
另一种方法,对于构建不寻常的结构最有用,是使用 'Glycosylation wizard'( Seach | Glycosylation | Glycosylation wizard )– 也可以在 'Simple modifications' 的弹出菜单中使用。 在向导中,您首先输入基础质量。这是附着在碳水化合物上的任何东西,可以是肽段或衍生试剂。然后您选择 N-连接、O-连接或其他糖基化。对于 N-连接,您然后选择要使用核心结构扩展的结构类型,然后在编辑器处结束,您可以在其中添加 'Sugars.mod' 中定义的任何类型的碳水化合物。 标准糖可以通过按下相应的按钮输入,请注意,糖仅按基本类型列出(例如,Hexose 涵盖半乳糖、葡萄糖和甘露糖),因为您无法使用质谱区分这些异构体。当您添加残基时,'Step back' 按钮亮起,使您能够"撤销"选择并重建您的结构。
在线留言尊敬的客户朋友,如您有任何意见建议,请通过下表反馈给我们,我们会尽快与您联系。
|
|
|
||||||||||||||||||||||||