
|
使用状态空间简化ARIMA建模:基于TSMT 4.0的通胀建模来源:Aptech 官方博客 · 作者:Eric · 发表时间:2025年6月2日 · 更新:2025年6月18日
引言状态空间模型是分析时间序列数据的强大工具,特别是在需要估计趋势或周期等不可观测成分时。但传统上,即使对于像ARIMA这样常见的模型,设置这些模型也可能非常繁琐。 GAUSS 本文将使用来自美联储经济数据库(FRED)的最新数据,重温我们之前的通胀建模示例。在此过程中,我们将演示 为什么在TSMT中使用
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 成员 | 描述 |
|---|---|
amo.aic |
Akaike信息准则值。 |
amo.b |
估计的模型系数(Kx1向量)。 |
amo.e |
拟合模型的残差(Nx1向量)。 |
amo.ll |
模型的对数似然值。 |
amo.sbc |
Schwarz贝叶斯准则值。 |
amo.lrs |
似然比统计量向量(Lx1)。 |
amo.vcb |
估计系数的协方差矩阵(KxK)。 |
amo.mse |
残差的均方误差。 |
amo.sse |
误差平方和。 |
amo.ssy |
因变量的总平方和。 |
amo.rstl |
kalmanResult 结构实例,包含卡尔曼滤波结果。 |
amo.tsmtDesc |
tsmtModelDesc 结构实例,包含模型描述详情。 |
amo.sumStats |
tsmtSummaryStats 结构实例,包含汇总统计量。 |
今天,我们将使用一个简单(尽管朴素)的通胀模型。该模型基于从 FRED CPIAUCNS月度数据集创建的CPI通胀指数。
首先,我们将直接从FRED数据库加载和准备数据。
使用 fred_load 和 fred_set 过程,我们将:
// 设置观测开始日期
fred_params = fred_set("observation_start", "1971-01-01");
// 指定单位为连续复利年化变化率
fred_params = fred_set("units", "cca");
// 指定要拉取的序列
series = "CPIAUCNS";
// 从FRED拉取数据
cpi_data = fred_load(series, fred_params);
// 预览数据
head(cpi_data);
这将输出前五个观测值:
date CPIAUCNS
1971-01-01 0.0000000
1971-02-01 3.0112900
1971-03-01 3.0037600
1971-04-01 2.9962600
1971-05-01 5.9701600
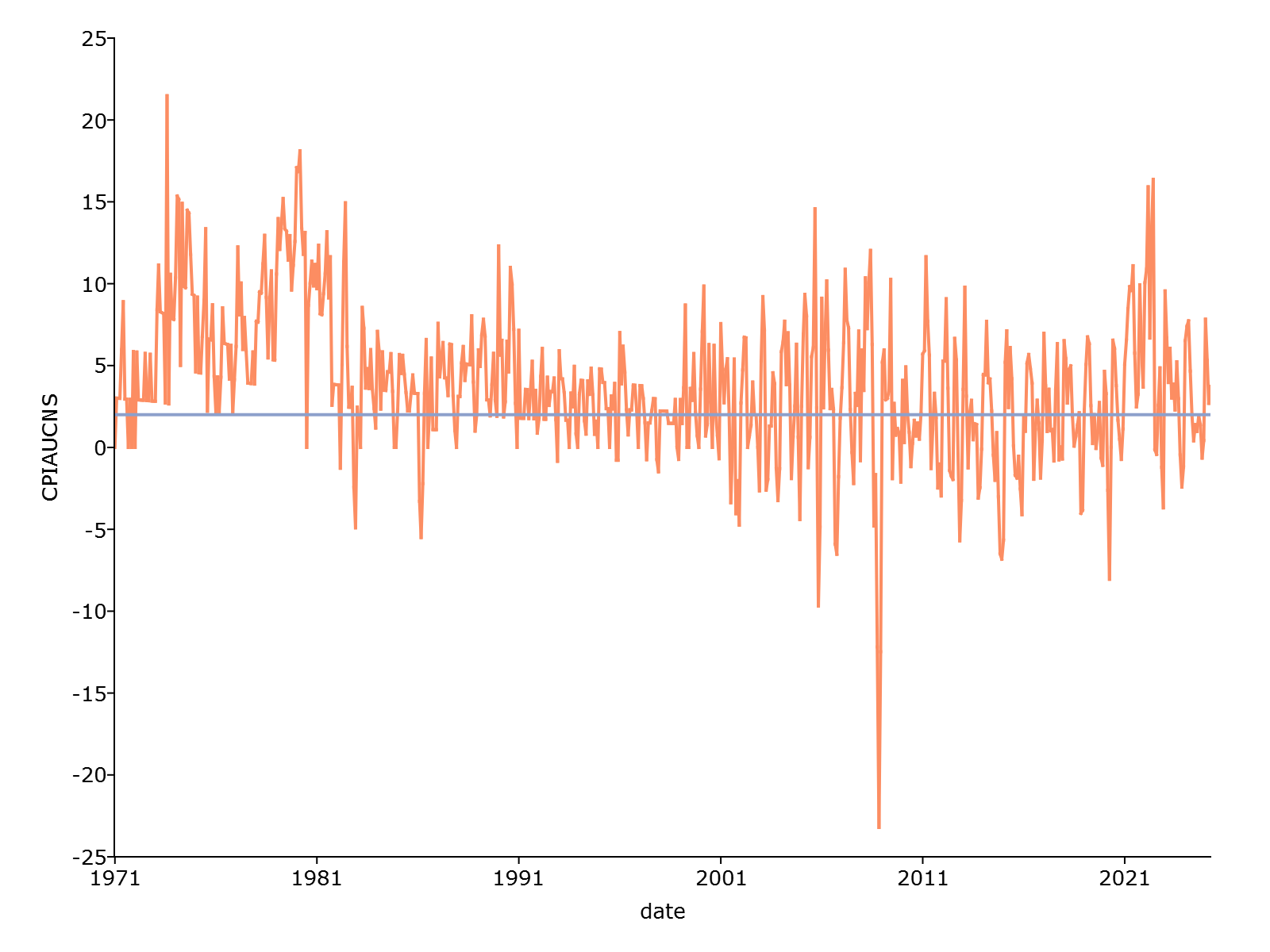
为进一步预览我们的数据,让我们使用 plotXY 过程和公式字符串创建一个通胀系列的快速图表:
plotXY(cpi_data, "CPIAUCNS~date");
为了更直观,让我们添加一条参考线来可视化美联储的长期平均通胀目标(2%):
// 在2%处添加通胀目标线 plotAddHLine(2);
最后再做一个可视化,让我们看看5年(60个月)的移动平均线:
// 计算移动平均 ma_5yr = movingAve(cpi_data[., "CPIAUCNS"], 60); // 添加到时间序列图 plotXY(cpi_data[., "date"], ma_5yr); // 在2%处添加通胀目标线 plotAddHLine(2);
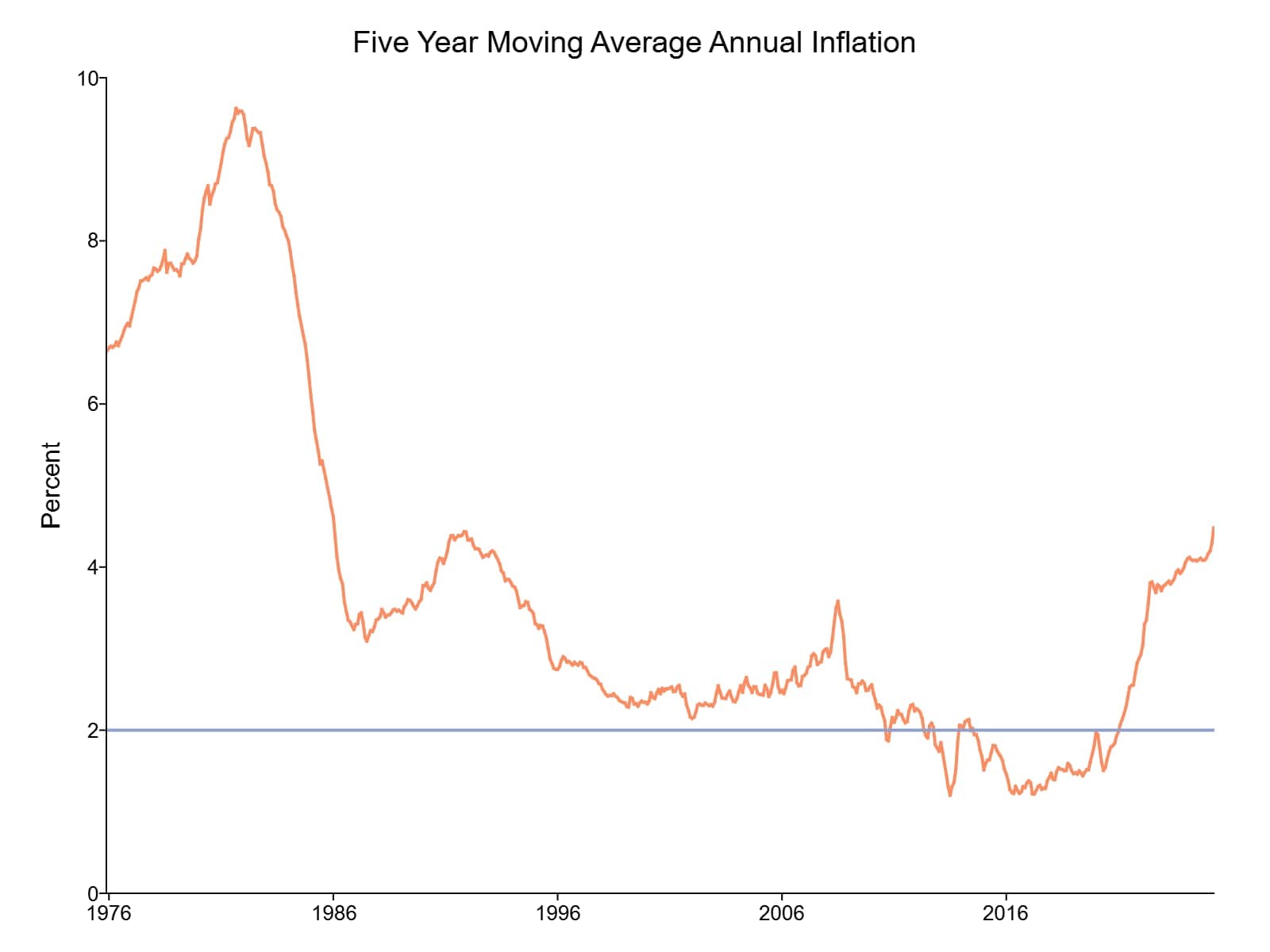
移动平均图突出了长期趋势,过滤了短期波动和噪声:
在估计之前,我们将进行最后一项转换,将"CPIAUCNS"的值从百分比转换为小数:
cpi_data[., "CPIAUCNS"] = cpi_data[., "CPIAUCNS"]/100;
fred_load过程需要有效的API密钥。要从FRED直接下载数据到GAUSS,您必须从 FRED 获取API密钥并在GAUSS中设置。有关从FRED导入数据的更多详情,请参阅我们之前的博客文章 将FRED数据导入GAUSS。
现在我们已经加载了数据,准备使用arimaSS来估计模型。我们从简单的AR(2)模型开始。基于之前的可视化,包含常数项但不包含趋势项是合理的,因此我们将对这些选项使用默认设置。
call arimaSS(cpi_data, 2);
关于这一点,有几点需要注意:
arimaSS 之前移除日期向量。大多数 TSMT 函数允许你在时间序列中包含日期向量。实际上,这是推荐的做法,GAUSS会自动检测并使用日期向量生成更具信息性的结果报告。call 关键字将其直接打印到屏幕上。详细的估计结果将打印到屏幕上:
================================================================================
模型: ARIMA(2,0,0) 因变量: CPIAUCNS
时间跨度: 1971-01-01: 有效样本量: 652
2025-04-01
SSE: 0.839 自由度: 648
对数似然: -1244.565 RMSE: 0.036
AIC: -2497.130 SEE: 0.210
SBC: -2463.210 Durbin-Watson: 1.999
R-squared: 0.358 Rbar-squared: 0.839
================================================================================
系数 估计值 标准误 T统计量 P值
--------------------------------------------------------------------------------
常数项 0.03832 0.00349 10.97118 0.00000
CPIAUCNS L(1) 0.59599 0.03715 16.04180 0.00000
CPIAUCNS L(2) 0.00287 0.03291 0.08726 0.93046
Sigma2 CPIAUCNS 0.00129 0.00007 18.05493 0.00000
================================================================================
从结果中有一些有趣的发现:
CPIAUCNS L(2)系数。unknown。arimaSS过程目前不提供内置的最优滞后选择。但是,我们可以编写一个简单的 for 循环,使用结构数组来识别最佳滞后长度。
我们的目标是选择具有最低AIC的模型,最大允许滞后数为6。
两个工具将帮助我们完成这项任务:
// 设置最大滞后数 maxlags = 6; // 声明单个数组 struct arimamtOut amo; // 重塑以创建结构数组 amo = reshape(amo, maxlags, 1); // AIC存储向量 aic_vector = zeros(maxlags, 1);
接下来,我们将循环遍历模型。在每次迭代中,我们将:
arimamtOut 结构中// 循环遍历滞后可能性
for i(1, maxlags, 1);
// 修剪数据以保持样本量一致性
y_i = trimr(cpi_data, maxlags-i, 0);
// 估计当前的 AR(i) 模型
amo[i] = arimaSS(y_i, i);
// 存储AIC便于比较
aic_vector[i] = amo[i].aic;
endfor;
最后,我们将使用 minindc 过程来查找最小AIC的索引:
// 最优滞后等于最小AIC的位置 opt_lag = minindc(aic_vector); // 打印最优滞后数 print "Optimal lags:"; opt_lag; // 选择最终的输出结构 struct arimamtOut amo_final; amo_final = amo[opt_lag];
基于最小AIC的最优滞后数为8,得到以下结果:
================================================================================
模型: ARIMA(8,0,0) 因变量: CPIAUCNS
时间跨度: 1971-01-01: 有效样本量: 652
2025-04-01
SSE: 0.803 自由度: 642
对数似然: -1258.991 RMSE: 0.035
AIC: -2537.982 SEE: 0.080
SBC: -2453.182 Durbin-Watson: 1.998
R-squared: 0.385 Rbar-squared: 0.939
================================================================================
系数 估计值 标准误 T统计量 P值
--------------------------------------------------------------------------------
常数项 0.03824 0.00512 7.46526 0.00000
CPIAUCNS L(1) 0.58055 0.03917 14.82047 0.00000
CPIAUCNS L(2) -0.03968 0.04730 -0.83883 0.40156
CPIAUCNS L(3) -0.01156 0.05062 -0.22833 0.81939
CPIAUCNS L(4) 0.09288 0.04151 2.23749 0.02525
CPIAUCNS L(5) 0.02322 0.04773 0.48639 0.62669
CPIAUCNS L(6) -0.06863 0.04505 -1.52333 0.12767
CPIAUCNS L(7) 0.16048 0.04038 3.97391 0.00007
CPIAUCNS L(8) -0.00313 0.02778 -0.11281 0.91018
Sigma2 CPIAUCNS 0.00123 0.00007 18.05512 0.00000
================================================================================
arimaSS函数提供了一种简化的方法来估计状态空间形式的ARIMA模型,消除了手动指定系统矩阵和初始值的需要。这使得探索模型、试验滞后结构和生成预测更加容易,特别是对于可能不熟悉状态空间建模的用户。
尊敬的客户朋友,如您有任何意见建议,请通过下表反馈给我们,我们会尽快与您联系。
联系我们 |
|||
微信公众号 |
咨询微信 |
企业店铺 |
|
|
 |
 |
 |
| (节假日期间办公室座机如无人接听,请选择其他联系方式,感谢理解!祝您节日快乐!) | |||
| 联系我们 | 快速链接 | 相关产品 | ©2026 上海卡贝信息技术有限公司
|
|---|---|---|---|
|
|
|
|