有界参数的MLE估计:一种更简洁的方法
来源:Aptech 官方博客 ·
引言
在数据分析应用中,参数存在边界是很自然的事情:方差不能为负,GARCH系数必须和为小于1以确保平稳性,混合比例介于0和1之间。
当你通过极大似然法估计这些模型时,优化器不仅需要在解处尊重这些边界,在整个搜索过程中也必须如此。如果优化搜索进入无效区域,可能会影响结果的可靠性和收敛性。例如,负方差会产生复数,非平稳的GARCH会产生爆炸式预测,或似然函数变得毫无意义。
GAUSS 26.0.1 引入了 minimize,这是十多年来GAUSS首个全新的优化器,能够干净利落地处理这一问题。
minimize 优化器允许您直接指定边界,GAUSS 会在内部确保每次迭代的参数都保持在可行域内。不再需要对数变换、惩罚函数或双重检查。
在今天的博客中,我们将通过两个示例演示新的 minimize 函数:
- 方差参数必须为正的 GARCH 估计
- 两个方差分量都必须为正的随机前沿模型
在这两种情况下,有界优化都使估计更加简便,并使结果与理论保持一致。
为什么边界很重要
要理解这在实际中的重要性,让我们看一个熟悉的例子。考虑一个 GARCH(1,1) 模型:
σ²t = ω + α ε²t-1 + β σ²t-1
为了使该模型定义良好且具有经济意义:
- 基准方差必须为正(ω > 0)
- 冲击和持续性必须对方差有非负贡献(α ≥ 0, β ≥ 0)
- 模型必须是平稳的(α + β < 1)
传统的变通方法是估计变换后的参数,例如用 log(ω) 代替 ω,然后再转换回来。这种方法虽然可行,但会扭曲优化曲面,并使标准误的计算复杂化。你估计的不是你关心的参数,而是参数的变换形式,并希望数值计算能够正常工作。
有了有界优化,你可以直接估计 ω、α 和 β,优化器在整个过程中都会遵守约束条件。
示例1:商品收益率的 GARCH(1,1) 模型
让我们在一个包含248个商品价格收益率观测值的数据集上估计 GARCH(1,1) 模型(该数据包含在 GAUSS 26 的示例目录中)。
第一步:数据和似然函数
首先,我们加载数据并指定对数似然目标函数。
// 加载收益率数据(随GAUSS提供)
fname = getGAUSShome("examples/df_returns.gdat");
returns = loadd(fname, "rcpi");
// GARCH(1,1) 负对数似然函数
proc (1) = garch_negll(theta, y);
local omega, alpha, beta_, sigma2, ll, t;
omega = theta[1];
alpha = theta[2];
beta_ = theta[3];
sigma2 = zeros(rows(y), 1);
// 以样本方差初始化
sigma2[1] = stdc(y)^2;
// 方差递推
for t (2, rows(y), 1);
sigma2[t] = omega + alpha * y[t-1]^2 + beta_ * sigma2[t-1];
endfor;
// 高斯对数似然
ll = -0.5 * sumc(ln(2*pi) + ln(sigma2) + (y.^2) ./ sigma2);
retp(-ll); // 返回负值用于最小化
endp;
第二步:设置优化
现在设置带边界约束的优化:
- ω > 0(较小的正数下界以避免数值问题)
- α ≥ 0
- β ≥ 0
由于 minimize 处理的是简单的盒约束,我们对 α 和 β 施加单独的上界,以使优化器保持在合理区域内。我们将在估计后验证平稳性条件 α + β < 1。
// 初始值
theta0 = { 0.00001, // omega(较小,让数据说话)
0.05, // alpha
0.90 }; // beta
// 设置 minimize
struct minimizeControl ctl;
ctl = minimizeControlCreate();
// 边界:所有参数为正,alpha + beta < 1
ctl.bounds = { 1e-10 1, // omega in [1e-10, 1]
0 1, // alpha in [0, 1]
0 0.9999 }; // beta in [0, 0.9999]
我们将 β 的上界设为略低于1,以避免在边界附近出现数值问题,因为此时似然曲面可能变得平坦且不稳定。
第三步:运行模型
最后,我们调用 minimize 来运行模型。
// 估计
struct minimizeOut out;
out = minimize(&garch_negll, theta0, returns, ctl);
结果与可视化
估计完成后,我们提取条件方差序列并确认平稳性条件:
// 提取估计值
omega_hat = out.x[1];
alpha_hat = out.x[2];
beta_hat = out.x[3];
print "omega = " omega_hat;
print "alpha = " alpha_hat;
print "beta = " beta_hat;
print "alpha + beta = " alpha_hat + beta_hat;
print "迭代次数: " out.iterations;
输出:
omega = 0.0000070
alpha = 0.380
beta = 0.588
alpha + beta = 0.968
迭代次数: 39
有几个值得注意的结果:
- 高持续性(α + β ≈ 0.97)意味着波动冲击衰减缓慢。
- 相对较高的 α(0.38)表明近期冲击对方差有显著的即时影响。
- 优化在39次迭代后收敛,所有参数在整个过程中都保持在边界内。没有无效的方差评估,没有数值异常。
将条件方差与原始序列一起可视化可以提供进一步的洞察:
// 计算条件方差序列用于绘图
T = rows(returns);
sigma2_hat = zeros(T, 1);
sigma2_hat[1] = stdc(returns)^2;
for t (2, T, 1);
sigma2_hat[t] = omega_hat + alpha_hat * returns[t-1]^2 + beta_hat * sigma2_hat[t-1];
endfor;
// 绘制收益率和条件波动率
struct plotControl plt;
plt = plotGetDefaults("xy");
plotSetTitle(&plt, "GARCH(1,1): 收益率与条件波动率");
plotSetYLabel(&plt, "收益率 / 波动率");
plotLayout(2, 1, 1);
plotXY(plt, seqa(1, 1, T), returns);
plotLayout(2, 1, 2);
plotSetTitle(&plt, "条件标准差");
plotXY(plt, seqa(1, 1, T), sqrt(sigma2_hat));
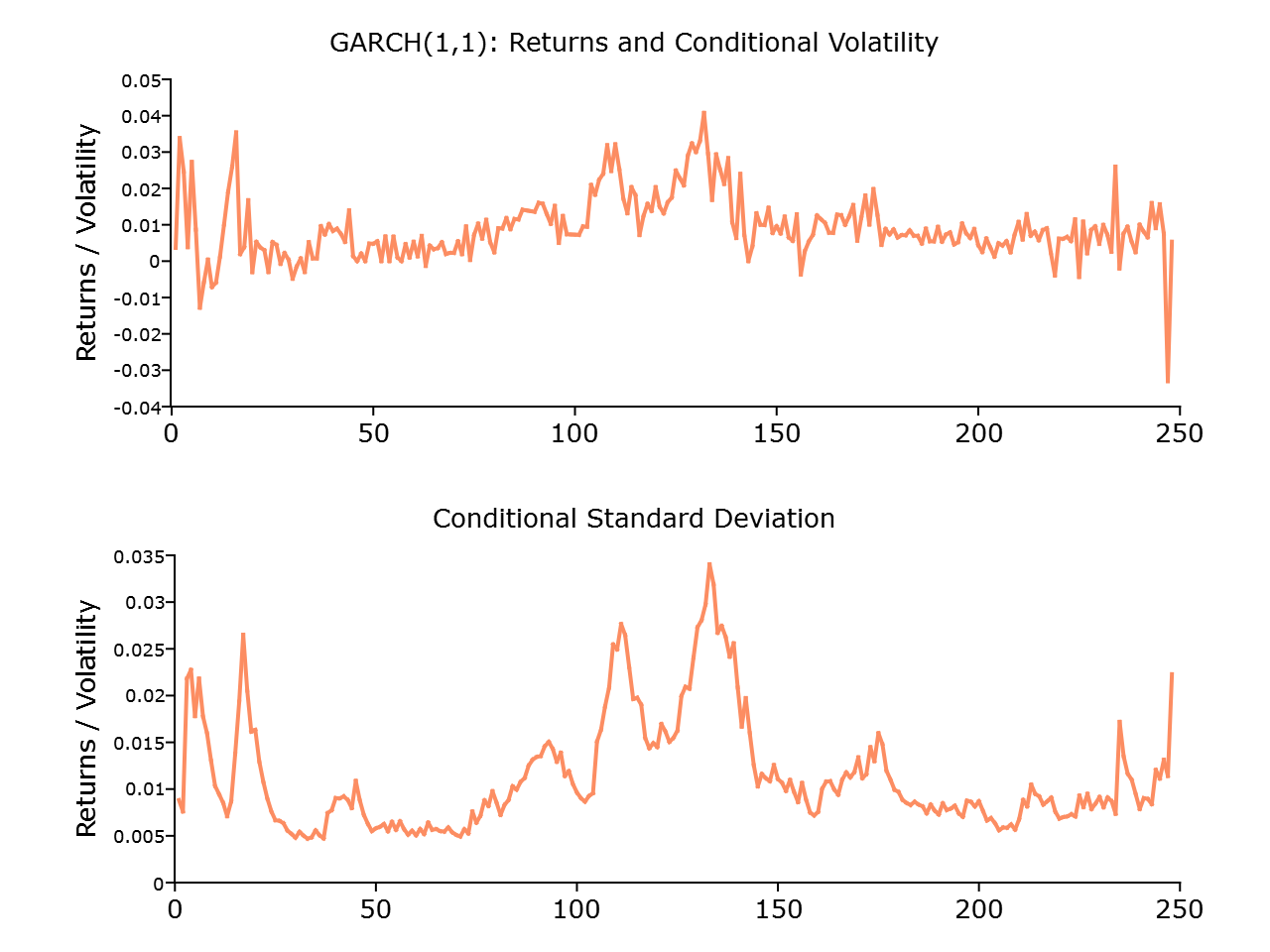
该图显示了波动聚集现象:高波动期往往持续存在,这与我们在商品市场中观察到的情况一致。
示例2:随机前沿模型
随机前沿分析将随机噪声与系统性无效率分离开来。它广泛应用于生产率分析,衡量企业在生产前沿之下的运营程度。
模型形式:
y = Xβ + v - u
其中:
- v ~ N(0, σ²v) — 对称噪声(测量误差、运气)
- u ~ N⁺(0, σ²u) — 单边无效率(总是减少产出)
两个方差分量都必须为正。如果优化器尝试 σ²v < 0 或 σ²u < 0,似然函数将涉及负数的平方根。
第一步:数据和似然函数
在本例中,我们将从带有无效率的柯布-道格拉斯生产函数中模拟数据。这使示例自成一体,让你能确切看到估计的内容。
// 模拟生产数据
rndseed 8675309;
n = 500;
// 投入要素(劳动、资本、原材料)
labor = exp(2 + 0.5*rndn(n, 1));
capital = exp(3 + 0.7*rndn(n, 1));
materials = exp(2.5 + 0.4*rndn(n, 1));
// 真实参数
beta_true = { 1.5, // 常数
0.4, // 劳动弹性
0.3, // 资本弹性
0.25 }; // 原材料弹性
sig2_v_true = 0.02; // 噪声方差
sig2_u_true = 0.08; // 无效率方差
// 生成带有噪声 (v) 和无效率 (u) 的产出
v = sqrt(sig2_v_true) * rndn(n, 1);
u = sqrt(sig2_u_true) * abs(rndn(n, 1)); // 半正态分布
X = ones(n, 1) ~ ln(labor) ~ ln(capital) ~ ln(materials);
y = X * beta_true + v - u; // 无效率减少产出
在模拟数据之后,我们指定用于最小化的对数似然函数:
// 随机前沿对数似然(半正态无效率)
proc (1) = sf_negll(theta, y, X);
local k, beta_, sig2_v, sig2_u, sigma, lambda;
local eps, z, ll;
k = cols(X);
beta_ = theta[1:k];
sig2_v = theta[k+1];
sig2_u = theta[k+2];
sigma = sqrt(sig2_v + sig2_u);
lambda = sqrt(sig2_u / sig2_v);
eps = y - X * beta_;
z = -eps * lambda / sigma;
ll = -0.5*ln(2*pi) + ln(2) - ln(sigma)
- 0.5*(eps./sigma).^2 + ln(cdfn(z));
retp(-sumc(ll));
endp;
第二步:设置优化
与之前的示例一样,我们从初始值开始。对于此模型,我们运行 OLS 并使用残差方差作为初始值:
// OLS 获取初始值
beta_ols = invpd(X'X) * X'y;
resid = y - X * beta_ols;
sig2_ols = meanc(resid.^2);
// 初始值:将残差方差在噪声和无效率之间分配
theta0 = beta_ols | (0.5 * sig2_ols) | (0.5 * sig2_ols);
我们让系数无边界,但约束方差为正:
// 边界:系数无界,方差为正
k = cols(X);
struct minimizeControl ctl;
ctl = minimizeControlCreate();
ctl.bounds = (-1e300 * ones(k, 1) | 0.001 | 0.001) ~ (1e300 * ones(k+2, 1));
第三步:运行模型
最后,我们调用 minimize 来估计模型:
// 估计
struct minimizeOut out;
out = minimize(&sf_negll, theta0, y, X, ctl);
结果与可视化
现在我们已经估计了模型,让我们检查结果。
// 提取估计值
k = cols(X);
beta_hat = out.x[1:k];
sig2_v_hat = out.x[k+1];
sig2_u_hat = out.x[k+2];
print "系数:";
print " 常数 = " beta_hat[1];
print " ln(劳动) = " beta_hat[2];
print " ln(资本) = " beta_hat[3];
print " ln(原材料) = " beta_hat[4];
print "";
print "方差分量:";
print " sig2_v (噪声) = " sig2_v_hat;
print " sig2_u (无效率) = " sig2_u_hat;
print " 无效率占比 = " sig2_u_hat / (sig2_v_hat + sig2_u_hat);
print "";
print "迭代次数: " out.iterations;
输出系数和方差分量:
系数:
常数 = 1.51
ln(劳动) = 0.39
ln(资本) = 0.31
ln(原材料) = 0.24
方差分量:
sig2_v (噪声) = 0.022
sig2_u (无效率) = 0.087
无效率占比 = 0.80
迭代次数: 38
估计结果相当好地恢复了真实参数。方差比(≈ 0.80)告诉我们,大部分残差变异是系统性无效率,而非测量误差——这对政策制定具有重要意义。
我们还可以计算并绘制企业层面的效率得分:
// 计算效率估计(Jondrow et al. 1982)
eps = y - X * beta_hat;
sigma = sqrt(sig2_v_hat + sig2_u_hat);
lambda = sqrt(sig2_u_hat / sig2_v_hat);
mu_star = -eps * sig2_u_hat / (sig2_v_hat + sig2_u_hat);
sig_star = sqrt(sig2_v_hat * sig2_u_hat / (sig2_v_hat + sig2_u_hat));
// E[u|eps] - 无效率的条件均值
u_hat = mu_star + sig_star * (pdfn(mu_star/sig_star) ./ cdfn(mu_star/sig_star));
// 技术效率: TE = exp(-u)
TE = exp(-u_hat);
// 绘制效率分布
struct plotControl plt;
plt = plotGetDefaults("hist");
plotSetTitle(&plt, "技术效率分布");
plotSetXLabel(&plt, "技术效率 (1 = 前沿)");
plotSetYLabel(&plt, "频数");
plotHist(plt, TE, 20);
print "平均效率: " meanc(TE);
print "最小效率: " minc(TE);
print "最大效率: " maxc(TE);
平均效率: 0.80
最小效率: 0.41
最大效率: 0.95
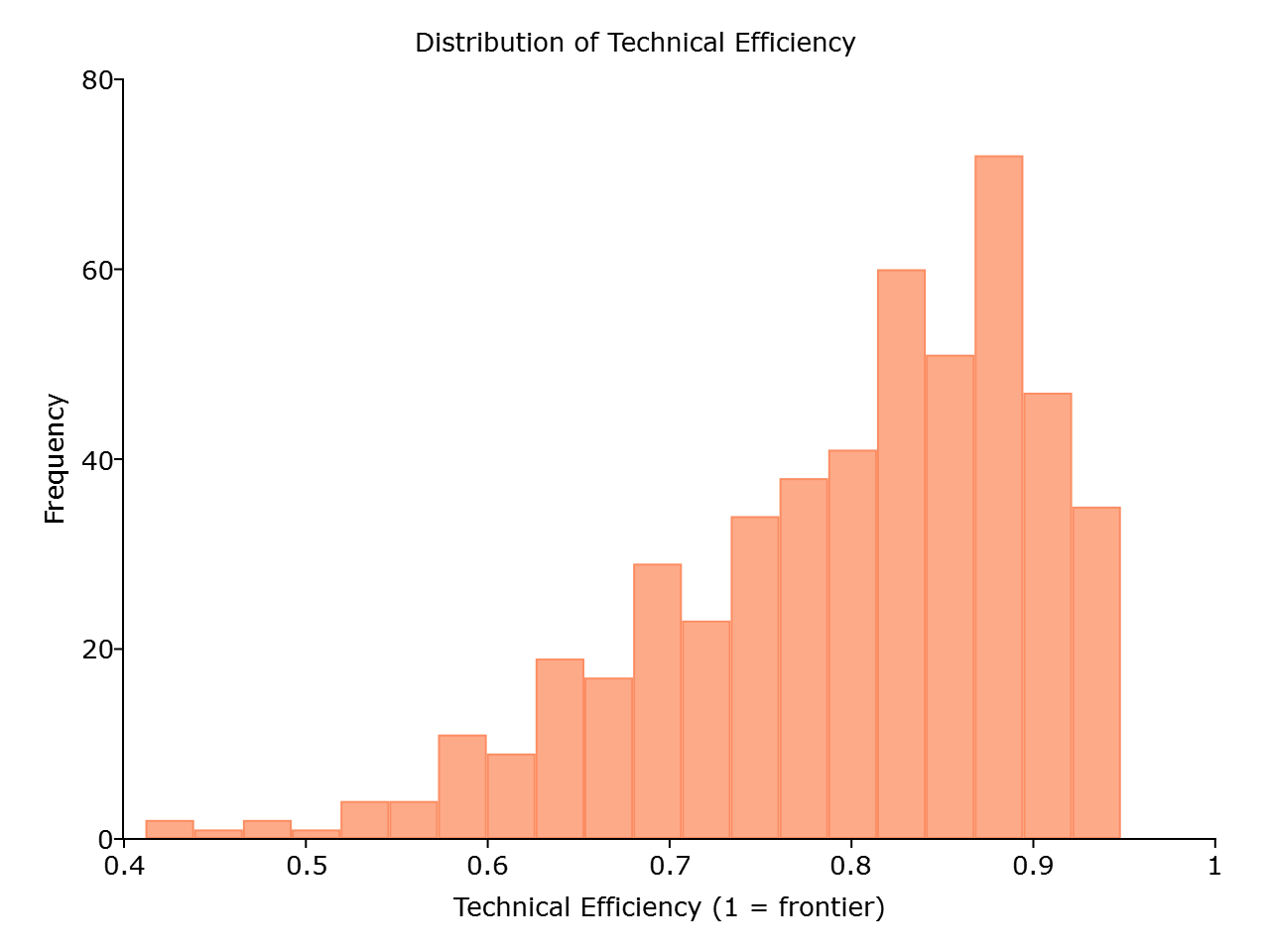
直方图显示了效率的巨大差异——一些企业接近前沿运营(TE ≈ 0.95),而其他企业的产出比其潜力低40-50%。这正是驱动生产率研究的那类洞察。
两个方差估计在整个优化过程中都保持为正。不需要对数变换,估计结果直接应用于我们关心的参数。
何时使用 minimize
minimize 过程专为一件事设计:带边界约束的优化。如果这就是你所需要的,它就是正确的工具。
对于上面的 GARCH 和随机前沿示例——以及大多数参数具有自然边界的 MLE 问题——minimize 可以直接处理。
结论
有界参数在计量经济学模型中随处可见:方差、波动率、概率、份额。GAUSS 26.0.1 提供了一种使用 minimize 处理它们的简洁方法。如我们所见,minimize:
- 在控制结构中设置边界
- 优化器在整个过程中遵守边界(不仅在解处)
- 无需对数变换或惩罚函数
- 包含在基础 GAUSS 中
如果你一直在使用变换或似然函数内部检查无效值来绕过参数边界,那么这就是更简洁的路径。
延伸阅读
在线留言
尊敬的客户朋友,如您有任何意见建议,请通过下表反馈给我们,我们会尽快与您联系。
|



