|
Stata/Python 集成第 4 部分:如何使用 Python 包
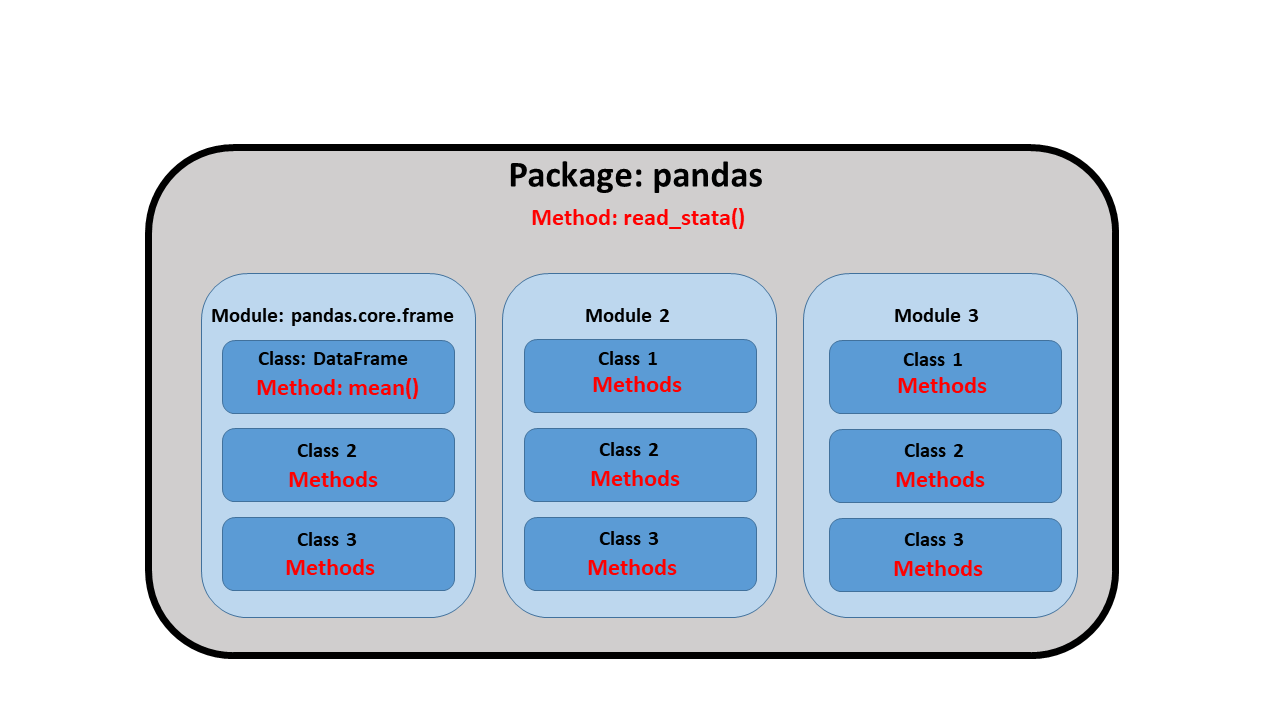
在上一篇文章中,我向您展示了如何使用 pip 为 Python 安装四个流行的包。今天,我想向您展示如何导入和使用 Python 包的基础知识。在此过程中,我们将学习一些重要的 Python 概念和术语。我将在下面的示例中使用 pandas 包,但这些思想和语法对于其他 Python 包也是相同的。 使用导入模块的包pandas 是一个流行的 Python 包,用于导入、导出和操作数据。该包包含不同的模块,用于处理不同的数据结构,如 series(序列)、data frames(数据框)和 panels(面板)。 让我们先输入 python which pandas 来验证 pandas 是否已安装在我们的系统中。 如果在结果中看不到路径,您需要按照我上一篇文章中的描述安装 pandas 包。 接下来,我们可以通过在代码块的顶部输入 import pandas 来告诉 Python 我们希望使用 pandas 包。这将从包中导入 pandas 模块。 然后,我们可以使用 pandas.read_stata() 方法从 Stata Press 网站读取 Stata 的 auto 数据集,并将其读取到名为 "auto" 的 pandas 数据框中。 术语 method(方法)用于描述模块中的函数。read_stata() 方法是 pandas 包中的一个函数,用于读取 Stata 数据集并将其转换为 pandas 数据框。 使用别名导入模块pandas 模块包含许多方法,我们可能最终会厌倦在每个方法之前输入 pandas。我们可以通过给模块分配别名来避免输入模块名称。我们可以通过输入 import modulename as alias 来为模块分配别名。在下面的代码块中,我输入了 import pandas as pd 来将别名 pd 分配给 pandas。现在,我可以通过输入 pd.read_stata() 而不是输入 pandas.read_stata() 来使用 read_stata() 方法。 在模块内使用方法和类模块是将包的功能细分以适应不同情况的一种方式。模块可以定义一组方法、类和变量。我们可以在 Python 语句中引用模块内的它们。例如,DataFrame 类包含在 pandas 包中的 pandas.core.frame 模块内。通常,我们只是简单地引用包中的类而省略模块的名称。例如,下面的代码块中的第四行使用 pandas 包中 DataFrame 类的 mean() 方法来估计 mpg 和 weight 的均值。 上面的代码块产生以下输出。 从模块导入方法和类您还可以从包内的模块导入类,并在使用类时省略模块名称或别名。下面的代码块中的第三行从 pandas 包导入 DataFrame 类。请注意,大小写很重要。现在,您可以通过输入 DataFrame.mean() 而不是 pd.DataFrame.mean() 来使用 mean() 方法。 使用别名导入函数和类您可能会厌倦每次估计均值时都输入 DataFrame.mean()。幸运的是,您可以通过输入 from modulename import classname as alias 为类分配别名。在下面的代码块的第三行中,我通过输入 from pandas import DataFrame as df 将别名 df 分配给 DataFrame 类。现在,我可以通过输入 df.mean() 而不是 DataFrame.mean() 来使用 mean() 方法。 回顾和结论让我们使用以下图表回顾我们学到的概念和术语。
Python 包是模块的集合。每个模块可以包含一组方法、类和变量。例如,pandas 包包含一组用于导入、导出和管理数据的类和方法。 方法是可以接受参数并执行某些操作的函数。方法可以是模块或类的一部分。 包内的方法通常细分为模块和类。包和类都可以包含许多方法。我们必须在使用它们的方法之前导入模块或类。 您可以在 pandas 用户指南中阅读有关 pandas 包的更多信息。 现在,我们已经完成了所有必要的准备工作,准备好进入有趣的部分了!在下一篇文章中,我将向您展示如何使用 Stata 从逻辑回归模型估计边际预测,并使用 Python 创建这些预测的三维曲面图。
在线留言尊敬的客户朋友,如您有任何意见建议,请通过下表反馈给我们,我们会尽快与您联系。
|
|
|
||||||||||||||||||||||||||